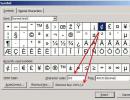
Таблица ascii с двоичным кодом. Кодировка ASCII (American standard code for information interchange) - базовая кодировка текста для латиницы
Excel для Office 365 Word для Office 365 Outlook для Office 365 PowerPoint для Office 365 Publisher для Office 365 Excel 2019 Word 2019 Outlook 2019 PowerPoint 2019 OneNote 2016 Publisher 2019 Visio профессиональный 2019 Visio стандартный 2019 Excel 2016 Word 2016 Outlook 2016 PowerPoint 2016 OneNote 2013 Publisher 2016 Visio 2013 Visio профессиональный 2016 Visio стандартный 2016 Excel 2013 Word 2013 Outlook 2013 PowerPoint 2013 Publisher 2013 Excel 2010 Word 2010 Outlook 2010 PowerPoint 2010 OneNote 2010 Publisher 2010 Visio 2010 Excel 2007 Word 2007 Outlook 2007 PowerPoint 2007 Publisher 2007 Access 2007 Visio 2007 OneNote 2007 Office 2010 Visio Стандартный 2007 Visio стандартный 2010 Меньше
В этой статье Вставка символа ASCII или Юникода в документЕсли вам нужно ввести только несколько специальных знаков или символов, можно использовать или сочетания клавиш. Список символов ASCII см. в следующих таблицах или статье Вставка букв национальных алфавитов с помощью сочетаний клавиш .
Примечания:
Вставка символов ASCIIЧтобы вставить символ ASCII, нажмите и удерживайте клавишу ALT, вводя код символа. Например, чтобы вставить символ градуса (º), нажмите и удерживайте клавишу ALT, затем введите 0176 на цифровой клавиатуре.
Для ввода чисел используйте цифровую клавиатуру , а не цифры на основной клавиатуре. Если на цифровой клавиатуре необходимо ввести цифры, убедитесь, что включен индикатор NUM LOCK.
Вставка символов ЮникодаЧтобы вставить символ Юникода, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить символ доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X. Все коды символов Юникода см. в .
Важно: Некоторые программы Microsoft Office, например PowerPoint и InfoPath, не поддерживают преобразование кодов Юникода в символы. Если вам необходимо вставить символ Юникода в одной из таких программ, используйте .
Примечания:
Если после нажатия клавиш ALT+X отображается неправильный символ Юникода, выберите правильный код, а затем снова нажмите ALT+X.
Кроме того, перед кодом следует ввести "U+". Например, если ввести "1U+B5" и нажать клавиши ALT+X, отобразится текст "1µ", а если ввести "1B5" и нажать клавиши ALT+X, отобразится символ "Ƶ".
Таблица символов - это программа, встроенная в Microsoft Windows, которая позволяет просматривать символы, доступные для выбранного шрифта.
С помощью таблицы символов можно копировать отдельные символы или группу символов в буфер обмена и вставлять их в любую программу, поддерживающую отображение этих символов. Открытие таблицы символов
В Windows 10 Введите слово "символ" в поле поиска на панели задач и выберите таблицу символов в результатах поиска.
В Windows 8 Введите слово "символ" на начальном экране и выберите таблицу символов в результатах поиска.
В Windows 7 нажмите кнопку Пуск , последовательно выберите Все программы , Стандартные , Служебные и щелкните Таблица символов .
Символы группируются по шрифту. Щелкните список шрифтов, чтобы выбрать подходящий набор символов. Чтобы выбрать символ, щелкните его, затем нажмите кнопку Выбрать . Чтобы вставить символ, щелкните правой кнопкой мыши нужное место в документе и выберите Вставить .
Коды часто используемых символовПолный список символов см. в на компьютере, таблице кодов символов ASCII или таблицах символов Юникода, упорядоченных по наборам .
|
Денежные единицы |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Юридические символы |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Математические символы |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Дроби |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Знаки пунктуации и диалектные символы |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Символы форм |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Коды часто используемых диакритических знаков
Полный список глифов и соответствующих кодов см. в .
|
По данным Международного Союза электросвязи, в 2016 году Интернетом с той или иной регулярностью пользовалось три с половиной миллиарда человек. Большинство из них даже не задумываются о том, что любые сообщения, посылаемые ими через ПК или мобильные гаджеты, а также тексты, которые отображаются на всевозможных мониторах, на самом деле представляют собой комбинации из 0 и 1. Такое представление информации называется кодированием. Оно обеспечивает и значительно облегчает осуществление ее хранения, обработки и передачи. В 1963 году была разработана американская кодировка ASCII, которой и посвящена данная статья.
Представление информации в компьютереС точки зрения любой электронно-вычислительной машины текст представляет собой набор отдельных символов. К их числу принадлежат не только буквы, включая заглавные, но и знаки препинания, цифры. Кроме того, используются спецсимволы «=»,«&», «(» и пробелы.
Множество символов, из которых состоит текст, называется алфавитом, а их количество — мощностью (обозначается, как N). Для ее определения используется выражение N = 2^b, где b — число бит или информационный вес конкретного символа.
Доказано, что алфавит мощностью 256 символов позволяет представить все необходимые символы.
Так как 256 представляет собой 8 степень двойки, то вес каждого символа равен 8 бит.
Единица измерения 8 бит называется 1 байтом, поэтому принято говорить, что любого символа в тексте, хранящемся на компьютере, занимает один байт памяти.

Любые тексты вводятся в память персонального компьютера посредством клавиш клавиатуры, на которых написаны цифры, буквы, знаки препинания и прочие символы. В оперативную память они передаются в двоичном коде, т. е. каждому символу сопоставляется привычный для человека десятеричный код, от 0 до 255, которому соответствует двоичный код - от 00000000 до 11111111.
Побайтовое кодирование символов позволяет процессору, выполняющему обработку текста, обращаться к каждому символу отдельно. В то же время 256 символов вполне достаточно для представления любой символьной информации.

Эта аббревиатура на английском расшифровывается как code for information interchange.
Еще на заре компьютеризации стало очевидно, что можно придумать самые разнообразные способы кодировки информации. Однако для переноса информации с одной ЭВМ на другую требовалось разработать единый стандарт. Так, в 1963 году в США появилась таблица кодировки ASCII. В ней любому символу компьютерного алфавита поставлен в соответствие его порядковый номер в двоичном представлении. Изначально кодировка ASCII использовалась только в Соединенных Штатах, а затем стала международным стандартом для ПК.
Коды ASCII делятся на 2 части. Международным стандартом считается лишь первая половина этой таблицы. В нее входят символы с порядковыми номерами от 0 (кодируется как 00000000) до 127 (код 01111111).
Порядковый номер | Кодировка текста ASCII | Символ |
0000 0000 - 0001 1111 | Символы с N от 0 до 31 называют управляющими. Их функцией является «руководство» процессом вывода текста на монитор или печатающее устройство, подача звукового сигнала и т.п. |
|
0010 0000 - 0111 1111 | Символы с N от 32 до 127 (стандартная часть таблицы) — прописные и строчные буквы латинского алфавита, 10-ные цифры, знаки препинания, а также различные скобки, коммерческие и др. символы. Символом 32 обозначается пробел. |
|
1000 0000 - 1111 1111 | Символы с N от 128 до 255 (альтернативная часть таблицы или кодовая страница) могут иметь различные варианты, каждый из которых имеет свой номер. Кодовая страница используется для задания национальных алфавитов, которые отличны от латинского. В частности, именно с ее помощью осуществляется кодировка ASCII для русских символов. |
В таблице кодировки прописные и идут друг за другом в алфавитном порядке, а цифры - по возрастанию значений. Такой принцип сохраняется и для русского алфавита.
Управляющие символыТаблица кодировки ASCII изначально создавалась для приема и передачи информации по такому уже давно не используемому устройству, как телетайп. В связи с этим в набор символов были включены непечатаемые, используемые в качестве команд для управления этим устройством. Подобные команды применялись и в таких докомпьютерных методах обмена сообщениями, как азбука Морзе, и пр.
Самым распространенным «телетайпным» символом является NUL (00, «нулевой»). Он и по сей день используется в большинстве языков программирования, обозначая признак конца строки.

Американский стандартный код необходим не только для ввода текстовой информации с клавиатуры. Его также используют в графике. В частности, в программе ASCII Art Maker изображения различных расширений представляют собой спектр символов кодировки ASCII.
Подобные продукты бывают двух типов: выполняющие функцию графических редакторов путем преобразования изображения в текст и конвертирующие «рисунки» в ASCII-графику. Например, известный смайлик является ярким примером кодировочного символа.
ASCII может использоваться и при создании документа HTML. В таком случае вы можете вводить некий набор знаков, а при просмотре страницы на экране появится символ, который соответствует данному коду.
ASCII необходим и для создания многоязычных сайтов, так как знаки, которые не входят в конкретную национальную таблицу, заменяются ASCII-кодами.

Для кодирования текстовой информации в кодировке ASCII изначально использовали 7 бит (один оставался пустым), однако сегодня она работает как 8-битная.
Буквы, располагающиеся в колонках, находящихся сверху и снизу, отличаются друг от друга только одним-единственным битом. Это значительно снижает степень сложности проверки.
Применение ASCII в Microsoft OfficeПри необходимости этот вид кодирования текстовой информации может использоваться в текстовых редакторах корпорации Microsoft, таких как Notepad и Office Word. Однако при наборе текста в таком случае будет невозможно использовать некоторые функции. Например, вы не сможете осуществлять выделение жирным шрифтом, так как кодировка ASCII сохраняет только смысл информации, игнорируя ее общий вид и форму.

Организация ISO приняла стандарты ISO 8859. Эта группа определяет восьмибитные кодировки для разных языковых групп. В частности, ISO 8859-1 — это Extended ASCII, представляющая собой таблицу для Соединенных Штатов и стран Западной Европы. А ISO 8859-5 — это таблица, применяемая для кириллицы, в том числе для русского языка.
По ряду исторических причин стандарт ISO 8859-5 использовался очень недолго.
Для русского языка на данный момент реально применяются кодировки:
- CP866 (Code Page 866) или DOS, которая часто называется альтернативной кодировкой ГОСТ. Она активно использовалась до середины 90-х годов прошлого века. На данный момент практически не используется.
- КОИ-8. Кодировка была разработана в 1970-80-е годы, и на данный момент это общепринятый стандарт для почтовых сообщений в Рунете. Она широко применяется и в ОС семейства Unix, в том числе Linux. «Русский» вариант КОИ-8 называется КОИ-8R. Кроме того, существуют версии и для других кириллических языков, например украинского.
- Code Page 1251 (CP 1251, Windows - 1251). Разработан корпорацией Microsoft для обеспечения поддержки русского языка в среде Windows.
Основным достоинством первого стандарта CP866 было сохранение псевдографических символов на тех же позициях, что и в Extended ASCII. Это позволяло запускать без изменений текстовые программы, зарубежного производства, такие как известный Norton Commander. На данный момент CP866 применяется для программ, разработанных под Windows, которые работают в полноэкранном текстовом режиме или в текстовых окнах, в том числе в FAR Manager.
Компьютерные тексты, написанные в кодировке CP866, в последнее время встречаются достаточно редко, однако именно она применяется для русских имен файлов в "Виндоус".
"Юникод"На данный момент наиболее широкое распространение получила именно эта кодировка. Коды "Юникода" разделены на области. Первая (от U+0000 до U+007F) включает символы набора ASCII с кодами. Затем следуют области знаков различных национальных письменностей, а также пунктуационные знаки и технические символы. Кроме того, часть кодов "Юникода" зарезервирована на случай возникновения необходимости включить новые символы в будущем.

Теперь вы знаете, что в кодировке ASCII каждый символ представляется как комбинация 8 нулей и единиц. Неспециалистам эта информация может показаться ненужной и неинтересной, но разве вам не хочет знать, что происходит «в мозгах» вашего ПК?!
Юникод (по-английски Unicode) - это стандарт кодирования символов. Проще говоря, это таблица соответствия текстовых знаков ( , букв, элементов пунктуации ) двоичным кодам. Компьютер понимает только последовательность нулей и единиц. Чтобы он знал, что именно должен отобразить на экране, необходимо присвоить каждому символу свой уникальный номер. В восьмидесятых, знаки кодировали одним байтом, то есть восемью битами (каждый бит это 0 или 1). Таким образом получалось, что одна таблица (она же кодировка или набор) может вместить только 256 знаков. Этого может не хватить даже для одного языка. Поэтому, появилось много разных кодировок, путаница с которыми часто приводила к тому, что на экране вместо читаемого текста появлялись какие-то странные кракозябры. Требовался единый стандарт, которым и стал Юникод. Самая используемая кодировка - UTF-8 (Unicode Transformation Format) для изображения символа задействует от 1 до 4 байт.
СимволыСимволы в таблицах Юникода пронумерованы шестнадцатеричными числами. Например, кириллическая заглавная буква М обозначена U+041C. Это значит, что она стоит на пересечении строки 041 и столбца С. Её можно просто скопировать и потом вставить куда-либо. Чтобы не рыться в многокилометровом списке следует воспользоваться поиском. Зайдя на страницу символа, вы увидите его номер в Юникоде и способ начертания в разных шрифтах. В строку поиска можно вбить и сам знак, даже если вместо него отрисовывается квадратик, хотя бы для того, чтобы узнать, что это было. Ещё, на этом сайте есть специальные (и - случайные) наборы однотипных значков, собранные из разных разделов, для удобства их использования.
Стандарт Юникод - международный. Он включает знаки почти всех письменностей мира. В том числе и тех, которые уже не применяются. Египетские иероглифы, германские руны, письменность майя, клинопись и алфавиты древних государств. Представлены и обозначения мер и весов, нотных грамот, математических понятий.
Сам консорциум Юникода не изобретает новых символов. В таблицы добавляются те значки, которые находят своё применение в обществе. Например, знак рубля активно использовался в течении шести лет прежде чем был добавлен в Юникод. Пиктограммы эмодзи (смайлики) тоже сначала получили широкое применение в Япониии прежде чем были включены в кодировку. А вот товарные знаки, и логотипы компаний не добавляются принципиально. Даже такие распространённые как яблоко Apple или флаг Windows. На сегодняшний день, в версии 8.0 закодировано около 120 тысяч символов.
В компьютере понимается процесс ее преобразования в форму, позволяющую организовать более удобную передачу, хранение или автоматическую переработку этих данных. С этой целью используются различные таблицы. Кодировка ASCII — это первая система, разработанная в Соединенных Штатах для работы с англоязычным текстом, которая получила впоследствии распространение во всем мире. Ее описанию, особенностям, свойствам и дальнейшему использованию посвящена статья, представленная ниже.
Отображение и хранение информации в ЭВМСимволы на мониторе компьютера или того или иного мобильного цифрового гаджета формируются на основе наборов векторных форм всевозможных знаков и кода, позволяющего найти среди них тот символ, который необходимо вставить в нужное место. Он представляет собой последовательностей бит. Таким образом, каждому символу должен однозначно соответствовать набор нулей и единиц, которые стоят в определенном, уникальном порядке.
Как все начиналосьИсторически сложилось так, что первые ЭВМ были англоязычными. Для кодирования символьной информации в них было достаточно использовать всего лишь 7 бит памяти, тогда как для этой цели выделялся 1 байт, состоящий из 8 битов. Количество знаков, понимаемых компьютером в таком случае, было равно 128. В число таких символов входили английский алфавит с его знаками препинания, числа и некоторые специальные символы. Англоязычная семибитная кодировка с соответствующей таблицей (кодовой страницей), разработанная в 1963 году, была названа American Standard Code for Information Interchange. Обычно для ее обозначения использовалась и используется и по сей день аббревиатура «Кодировка ASCII».
Переход к мультиязычностиСо временем компьютеры стали широко использоваться и в неанглоговорящих странах. В связи с этим появилась нужда в кодировках, позволяющих использовать национальные языки. Было решено не изобретать велосипед, и взять за основу ASCII. Таблица кодировки в новой редакции значительно расширилась. Использование 8-го бита позволило переводить на компьютерный язык уже 256 символов.

Кодировка ASCII имеет таблицу, которая делится на 2 части. Общепринятым международным стандартом принято считать лишь ее первую половину. В нее входят:
- Символы с порядковыми номерами от 0 до 31, кодируемые последовательностями от 00000000 до 00011111. Они отведены для управляющих символов, которые руководят процессом вывода текста на экран или принтер, подачей звукового сигнала и т. п.
- Символы с NN в таблице от 32 до 127, кодируемые последовательностями от 00100000 до 01111111 составляют стандартную часть таблицы. В их число входят пробел (N 32), буквы латинского алфавита (строчные и прописные), десятизначные цифры от 0 до 9, знаки препинания, скобки разного начертания и другие символы.
- Символы с порядковыми номерами от 128 до 255, кодируемые последовательностями от 10000000 до 11111111. В их число включены буквы национальных алфавитов, отличные от латинского. Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.

К особенностям кодировки ASCII относится отличие букв «A» - «Z» нижнего и верхнего регистров только одним битом. Это обстоятельство значительно упрощает преобразование регистра, а также его проверку на принадлежность к заданному диапазону значений. Кроме того, все буквы в системае кодировки ASCII представляются собственными порядковыми номерами в алфавите, которые записаны 5 цифрами в двоичной системе счисления, перед которыми для букв нижнего регистра стоит 011 2 , а верхнего — 010 2 .
К числу особенностей кодировки ASCII можно причислить и представление 10 цифр - «0»-«9». Во второй системе счисления они начинаются с 00112, а заканчиваются 2-ми значениями чисел. Так, 0101 2 эквивалентно десятичному числу пять, поэтому символ «5» записывается как 0011 01012. Опираясь на сказанное, можно легко преобразовать двоично-десятичные числа в строку в кодировке ASCII посредством добавления слева битовой последовательности 00112 к каждому полубайту.

Как известно, для отображения текстов на языках группы юго-восточной Азии требуются тысячи знаков. Такое их количество никак не описывается в одном байте информации, поэтому даже расширенные версии ASCII уже не могли удовлетворять возросшие потребности пользователей из разных стран.
Так, возникла необходимость создания универсальной кодировки текста, разработкой которой при сотрудничестве со многими лидерами мировой IT-индустрии занялся консорциум "Юникод". Его специалистами была создана система UTF 32. В ней для кодирования 1 символа выделялось 32 бита, составляющих 4 байта информации. Главным недостатком было резкое увеличение объема необходимой памяти в целых 4 раза, что влекло за собой множество проблем.
В то же время для большинства стран с официальными языками, относящимися к индоевропейской группе, количество знаков, равное 2 32 , является более чем избыточным.
В результате дальнейшей работы специалистов из консорциума "Юникод" появилась кодировка UTF-16. Она стала тем вариантом преобразования символьной информации, которая устроила всех как по объему требуемой памяти, так и по числу кодируемых символов. Именно поэтому UTF-16 была принята по умолчанию и в ней для одного знака требуется зарезервировать 2 байта.
Даже эта достаточно продвинутая и удачная версия "Юникода" имела некоторые недостатки, и после перехода от расширенной версии ASCII к UTF-16 увеличивала вес документа в два раза.
В связи с этим было решено использовать кодировку переменной длины UTF-8. В таком случае каждый символ исходного текста кодируется последовательностью длиной от 1 до 6 байт.

Все знаки латинского алфавита в UTF-8 переменной длины кодируются в 1 байт, как в системе кодировки ASCII.
Особенностью ЮТФ-8 является то, что в случае текста на латинице без использования других символов, даже программы, не понимающие "Юникод", все равно позволят его прочитать. Иными словами, базовая часть кодировки текста ASCII просто переходит в состав новой UTF переменной длины. Кириллические знаки в ЮТФ-8 занимают 2 байта, а, например, грузинские — 3 байта. Созданием UTF-16 и 8 была решена основная проблема создания единого кодового пространства в шрифтах. С тех пор производителям шрифтов остается только заполнять таблицу векторными формами символов текста исходя из своих потребностей.
В различных операционных системах предпочтение отдается различным кодировкам. Чтобы иметь возможность читать и редактировать тексты, набранные в другой кодировке, применяются программы перекодировки русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики и позволяют читать текст вне зависимости от кодировки.

Теперь вы знаете, сколько символов в кодировке ASCII и, как и почему она была разработана. Конечно, сегодня наибольшее распространение в мире получил стандарт "Юникод". Однако нельзя забывать, что он создан на базе ASCII, поэтому следует по достоинству оценивать вклад его разработчиков в сферу IT.
Как известно, компьютер хранит информацию в двоичном виде, представляя её в качестве последовательности единиц и нулей. Чтобы перевести информацию в форму, удобную для человеческого восприятия, каждая уникальная последовательность цифр при отображении заменяется на соответствующий ей символ.
Одной из систем соотнесения бинарных кодов с печатными и управляющими символами является
При сегодняшнем уровне развития компьютерных технологий от пользователя не требуется знание кода каждого конкретного символа. Однако общее понимание того, как осуществляется кодирование, является крайне полезным, а для некоторых категорий специалистов и вовсе необходимым.
Создание ASCIIВ первоначальном виде кодировка была разработана в 1963 году и затем в течение 25 лет дважды обновлялась.
В исходном варианте таблица символов ASCII включала 128 символов, позже появилась расширенная версия, где первые 128 знаков были сохранены, а кодам с задействованным восьмым битом поставлены в соответствие отсутствовавшие ранее символы.
На протяжении многих лет данная кодировка являлась самой популярной в мире. В 2006 году ведущее место заняла Latin 1252, а с конца 2007 года по настоящее время лидирующую позицию прочно держит Юникод.
Компьютерное представление ASCIIКаждый ASCII-символ имеет собственный код, состоящий из 8 знаков, представляющих собой нуль или единицу. Минимальным числом в таком представлении является нуль (восемь нулей в двоичной системе), который и является кодом первого элемента в таблице.
Два кода в таблице были отведены под переключение между стандартной US-ASCII и её национальным вариантом.

После того как ASCII стала включать не 128, а 256 знаков, распространение получил вариант кодировки, при котором исходная версия таблицы была сохранена в первых 128 кодах с нулевым 8-м битом. Знаки национальной письменности хранились в верхней половине таблицы (128-255-я позиции).
Знать непосредственно коды символов ASCII пользователю не требуется. Разработчику программного обеспечения обычно достаточно знать номер элемента в таблице, чтобы при необходимости рассчитать его код, используя бинарную систему.
Русский языкПосле разработки в начале 70-х годов кодировок для скандинавских языков, китайского, корейского, греческого и др., созданием собственного варианта занялся и Советский Союз. Вскоре был разработан вариант 8-битной кодировки под названием КОИ8, сохраняющей первые 128 кодов символов ASCII и выделяющей столько же позиций под буквы национального алфавита и дополнительные знаки.
До внедрения Юникода КОИ8 доминировала в российском сегменте интернета. Существовали варианты кодировки как для русского, так и для украинского алфавита.
Проблемы ASCIIПоскольку количество элементов даже в расширенной таблице не превышало 256, возможность вмещения в одну кодировку нескольких различных письменностей отсутствовала. В 90-е годы в Рунете появилась проблема «крокозябр», когда тексты, набранные русскими символами ASCII, отображались некорректно.
Проблема заключалась в несоответствии кодов различных вариантов ASCII друг другу. Вспомним, что на позициях 128-255 могли располагаться различные знаки, и при смене одной кириллической кодировки на другую все буквы текста заменялись на другие, имеющие идентичный номер в другой версии кодировки.
Текущее состояниеС появлением Юникода популярность ASCII резко пошла на убыль.
Причина этого кроется в том факте, что новая кодировка позволила вместить знаки почти всех письменных языков. При этом первые 128 символов ASCII соответствуют тем же символам в Юникоде.

В 2000-м ASCII была самой популярной кодировкой в интернете и использовалась на 60 % проиндексированных «Гуглом» веб-страниц. Уже к 2012 году доля таких страниц упала до 17 %, а место самой популярной кодировки занял Юникод (UTF-8).
Таким образом, ASCII является важной частью истории информационных технологий, однако её использование в дальнейшем видится малоперспективным.